Dieses FAQ soll die häufigsten Fragen zur Vision Lab-Software beantworten. Wenn Sie die gesuchte Antwort nicht finden oder zusätzliche Fragen haben, können Sie uns jederzeit kontaktieren – wir helfen Ihnen gerne weiter.
Erste Schritte
Wie Anomalie-Erkennung funktioniert
Funktionen & Fähigkeiten
Integration & Automatisierung
IT & Infrastruktur
Monitoring & Qualitätssicherung
Preise & Support
Weitere Materialien
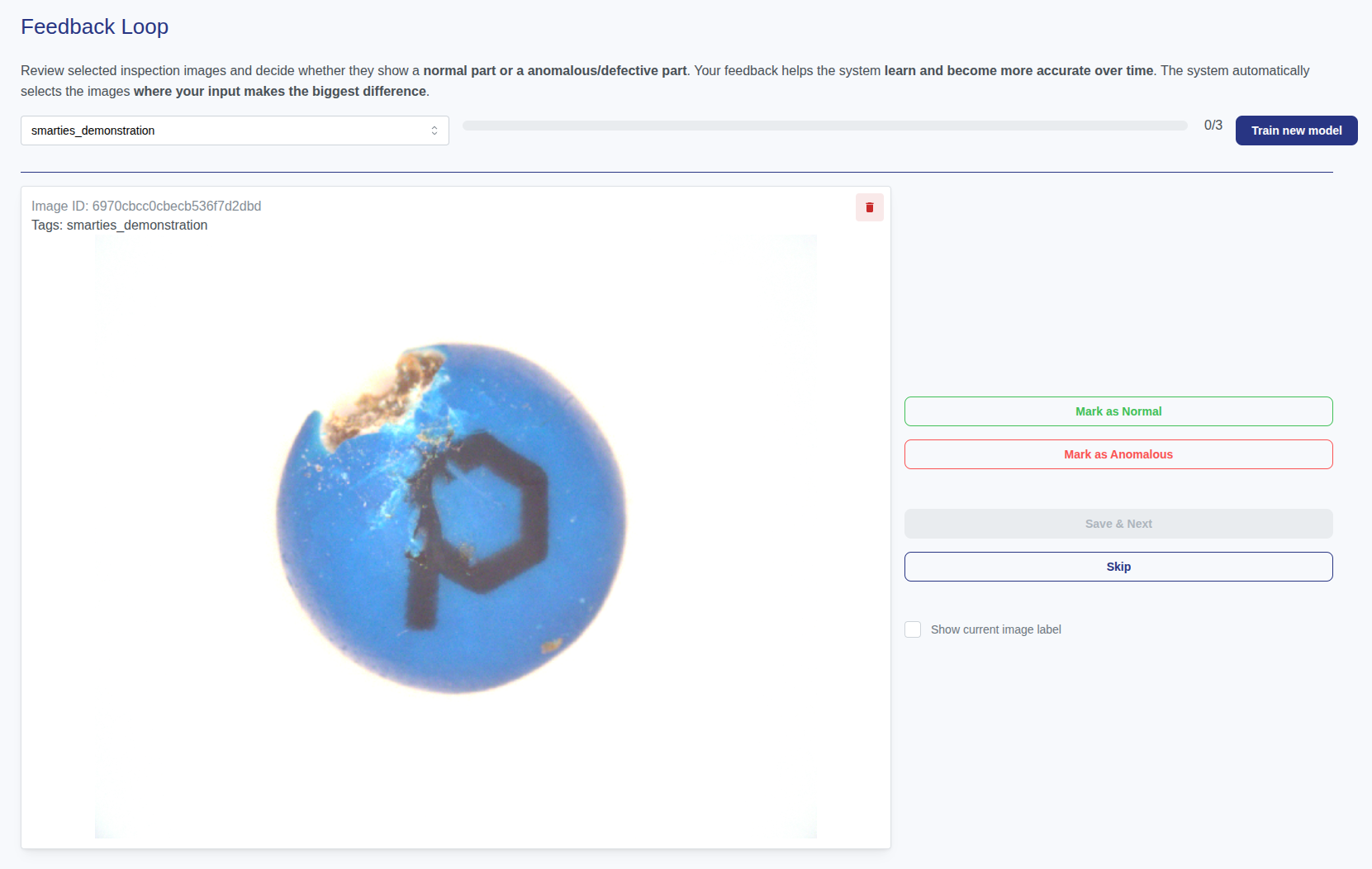
Feedback Loop für KI-basierte Anomalieerkennung: Präzisere Qualitätskontrolle durch Nutzerfeedback
Unser neues Feedback-Loop-Feature ermöglicht eine kontinuierliche Verbesserung der KI-basierten Anomalieerkennung durch gezielte Nutzerannotationen und intelligente Priorisierung unsicherer Fälle. So verbinden wir menschliche Expertise mit datengetriebener Optimierung und sichern stabile, [...]

Video Tutorials für das neue preML Vision Lab
Dieser Artikel sammelt aktuelle Video Tutorials für das preML Vision Lab. Vision Lab enthält verschiedene Funktionalitäten wie die Verwaltung von Bilddatensätzen, Training von KI-Modellen oder der Anzeige von Live-Systemen. [...]
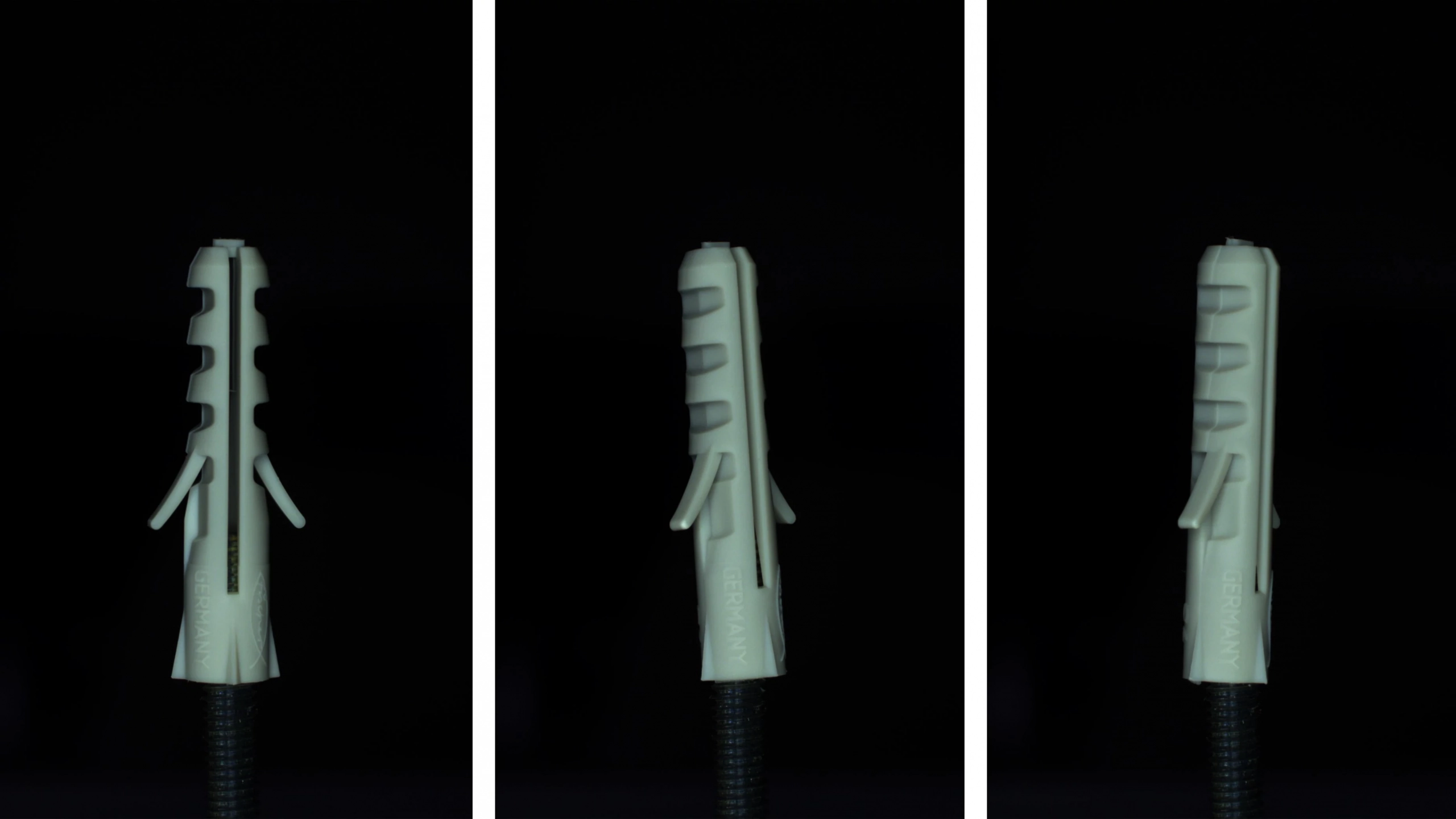
Wie erstelle ich einen hochwertigen Datensatz zur Anomalieerkennung?
Ein großer Vorteil von Anomalie-Erkennungsmodellen ist, dass sie ausschließlich mit Bildern trainiert werden, die das ideale Erscheinungsbild eines Objekts repräsentieren. Das bedeutet, man benötigt lediglich Aufnahmen von fehlerfreien Objekten. [...]
#syntheticData #computerVision #machineLearning #visualQualityControl